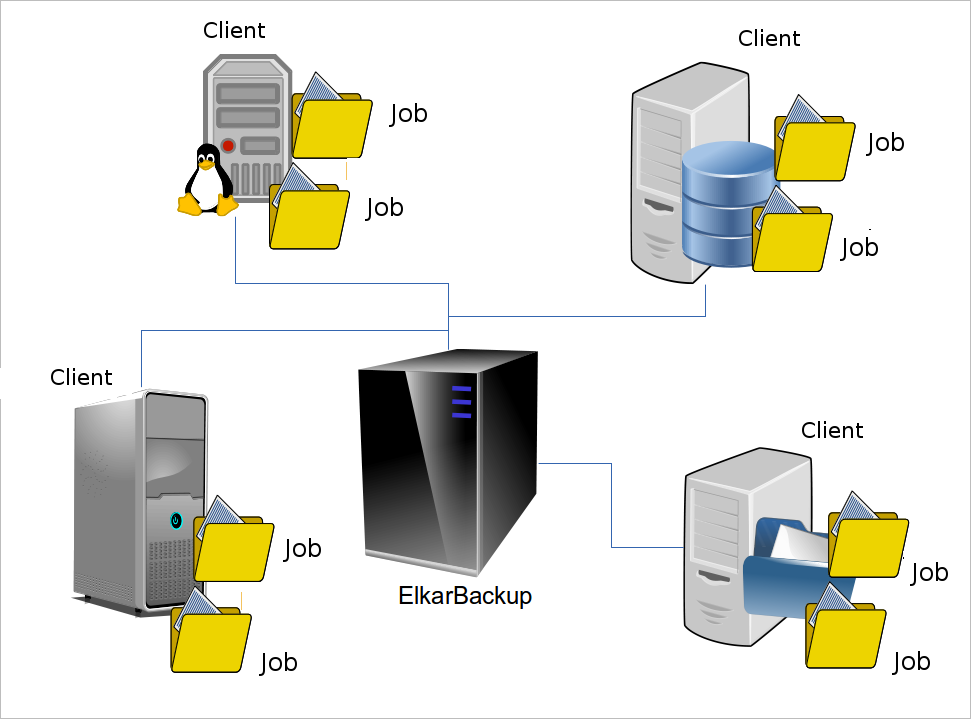
Clients and jobs
First of all, let's introduce what we call clients and jobs :
Client: A client is a host that contains the data we want to save. It could be any machine that supports ssh or rsync automated connectivity. In this manual we'll focus on GNU/Linux and Windows clients.
Job: Each root folder we want to save from each client. Each job has it's own configuration with it's own frequency, retention policy and backup location. A client could have (and usually it has) more than one job.
Connecting to the clients
Our Elkarbackup server will be able to get and copy data from multiple clients, but they need to communicate using rsync or ssh protocols.
As you know, this is in the box when we speak about GNU/Linux computers, but for Windows systems prior to Windows 10 we need help, so we will install the Cwrsync free edition to set up the rsync service in Windows clients.
With rsync managing the data transfer, we have an important advantage: Before to start transferring files, both sides (server and client) decide if it is necessary to copy each file, so they only transfer the files that have been changed and the new ones. It supposes more CPU work for the one that is sending the files (the client) and more I/O for the one that is receiving the files (the Elkarbackup server).
In GNU/Linux environments it is quite common to have to copy the same folders from some clients: configuration folders, logs, etc.
To avoid having to create the job configuration for each client, we can create and configure the jobs for the first one, and then clone all the configuration using the Clone button.
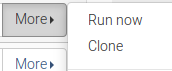
Once this is done we should modify the own and different parameters for each client (address, etc).